This guide dives deep into the inner workings of Matplotlib’s Figures, Axes, subplots and the very amazing GridSpec!Preliminaries
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
A Top-Down runnable Jupyter Notebook with the exact contents of this blog can be found here
An interactive version of this guide can be accessed on Google Colab
A word before we get started…
Although a beginner can follow along with this guide, it is primarily meant for people who have at least a basic knowledge of how Matplotlib’s plotting functionality works.
Essentially, if you know how to take 2 NumPy arrays and plot them (using an appropriate type of graph) on 2 different axes in a single figure and give it basic styling, you’re good to go for the purposes of this guide.
If you feel you need some introduction to basic Matplotlib plotting, here’s a great guide that can help you get a feel for introductory plotting using Matplotlib
From here on, I will be assuming that you have gained sufficient knowledge to follow along this guide.
Also, in order to save everyone’s time, I will keep my explanations short, terse and very much to the point, and sometimes leave it for the reader to interpret things (because that’s what I’ve done throughout this guide for myself anyway).
The primary driver in this whole exercise will be code and not text, and I encourage you to spin up a Jupyter notebook and type in and try out everything yourself to make the best use of this resource.
What this guide is and what it is not:
This is not a guide about how to beautifully plot different kinds of data using Matplotlib, the internet is more than full of such tutorials by people who can explain it way better than I can.
This article attempts to explain the workings of some of the foundations of any plot you create using Matplotlib.
We will mostly refrain from focusing on what data we are plotting and instead focus on the anatomy of our plots.
Setting up
Matplotlib has many styles available, we can see the available options using:
['seaborn-dark',
'seaborn-darkgrid',
'seaborn-ticks',
'fivethirtyeight',
'seaborn-whitegrid',
'classic',
'_classic_test',
'fast',
'seaborn-talk',
'seaborn-dark-palette',
'seaborn-bright',
'seaborn-pastel',
'grayscale',
'seaborn-notebook',
'ggplot',
'seaborn-colorblind',
'seaborn-muted',
'seaborn',
'Solarize_Light2',
'seaborn-paper',
'bmh',
'tableau-colorblind10',
'seaborn-white',
'dark_background',
'seaborn-poster',
'seaborn-deep']
We shall use seaborn. This is done like so:
Let’s get started!
# Creating some fake data for plotting
xs = np.linspace(0, 2 * np.pi, 400)
ys = np.sin(xs**2)
xc = np.linspace(0, 2 * np.pi, 600)
yc = np.cos(xc**2)
Exploration
The usual way to create a plot using Matplotlib goes somewhat like this:
fig, ax = plt.subplots(2, 2, figsize=(16, 8))
# `Fig` is short for Figure. `ax` is short for Axes.
ax[0, 0].plot(xs, ys)
ax[1, 1].plot(xs, ys)
ax[0, 1].plot(xc, yc)
ax[1, 0].plot(xc, yc)
fig.suptitle("Basic plotting using Matplotlib")
plt.show()
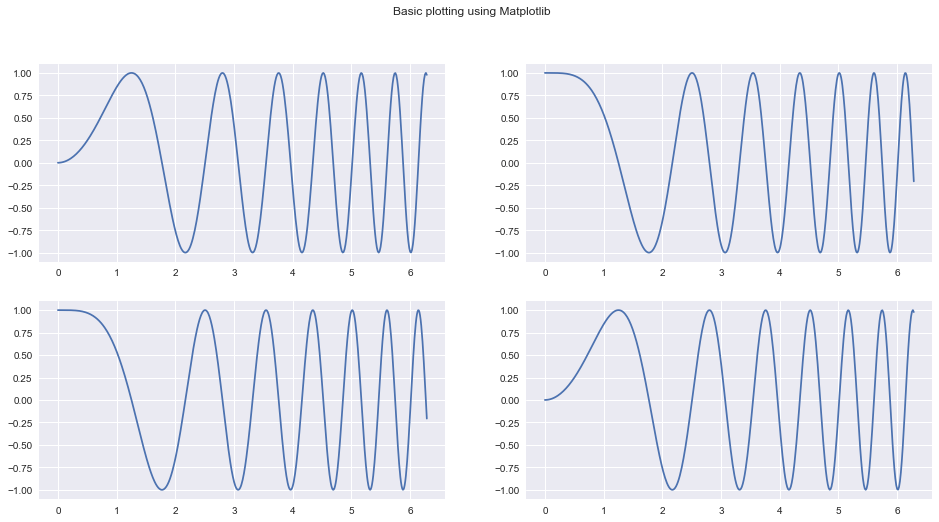
Our goal today is to take apart the previous snippet of code and understand all of the underlying building blocks well enough so that we can use them separately and in a much more powerful way.
If you’re a beginner like I was before writing this guide, let me assure you: this is all very simple stuff.
Going into plt.subplots documentation (hit Shift+Tab+Tab in a Jupyter notebook) reveals some of the other Matplotlib internals that it uses in order to give us the Figure and it’s Axes.
These include :
plt.subplotplt.figurempl.figure.Figurempl.figure.Figure.add_subplotmpl.gridspec.GridSpecmpl.axes.Axes
Let’s try and figure out what these functions / classes do.
A Figure in Matplotlib is simply your main (imaginary) canvas. This is where you will be doing all your plotting / drawing / putting images and what not. This is the central object with which you will always be interacting. A figure has a size defined for it at the time of creation.
You can define a figure like so (both statements are equivalent):
fig = mpl.figure.Figure(figsize=(10, 10))
# OR
fig = plt.figure(figsize=(10, 10))
Notice the word imaginary above. What this means is that a Figure by itself does not have any place for you to plot. You need to attach/add an Axes to it to do any kind of plotting. You can put as many Axes objects as you want inside of any Figure you have created.
An Axes:
- Has a space (like a blank Page) where you can draw/plot data.
- A parent
Figure
- Has properties stating where it will be placed inside it’s parent
Figure.
- Has methods to draw/plot different kinds of data in different ways and add custom styles.
You can create an Axes like so (both statements are equivalent):
ax1 = mpl.axes.Axes(fig=fig, rect=[0, 0, 0.8, 0.8], facecolor="red")
# OR
ax1 = plt.Axes(fig=fig, rect=[0, 0, 0.8, 0.8], facecolor="red")
#
The first parameter fig is simply a pointer to the parent Figure to which an Axes will belong.
The second parameter rect has four numbers : [left_position, bottom_position, height, width] to define the position of the Axes inside the Figure and the height and width with respect to the Figure. All these numbers are expressed in percentages.
A Figure simply holds a given number of Axes at any point of time
We will go into some of these design decisions in a few moments'
Recreating plt.subplots with basic Matplotlib functionality
We will try and recreate the below plot using Matplotlib primitives as a way to understand them better. We’ll try and be a slightly creative by deviating a bit though.
fig, ax = plt.subplots(2, 2)
fig.suptitle("2x2 Grid")
Text(0.5, 0.98, '2x2 Grid')
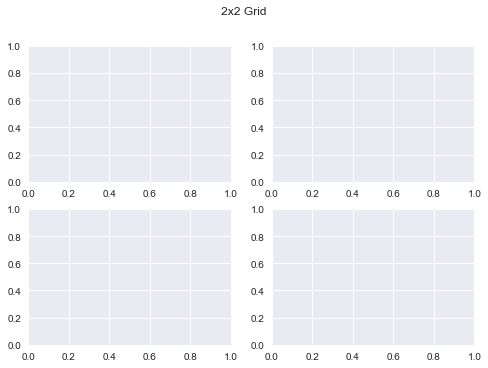
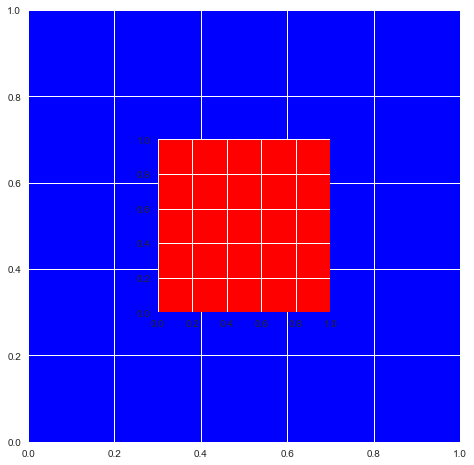
Let’s create our first plot using Matplotlib primitives:
# We first need a figure, an imaginary canvas to put things on
fig = plt.Figure(figsize=(6, 6))
# Let's start with two Axes with an arbitrary position and size
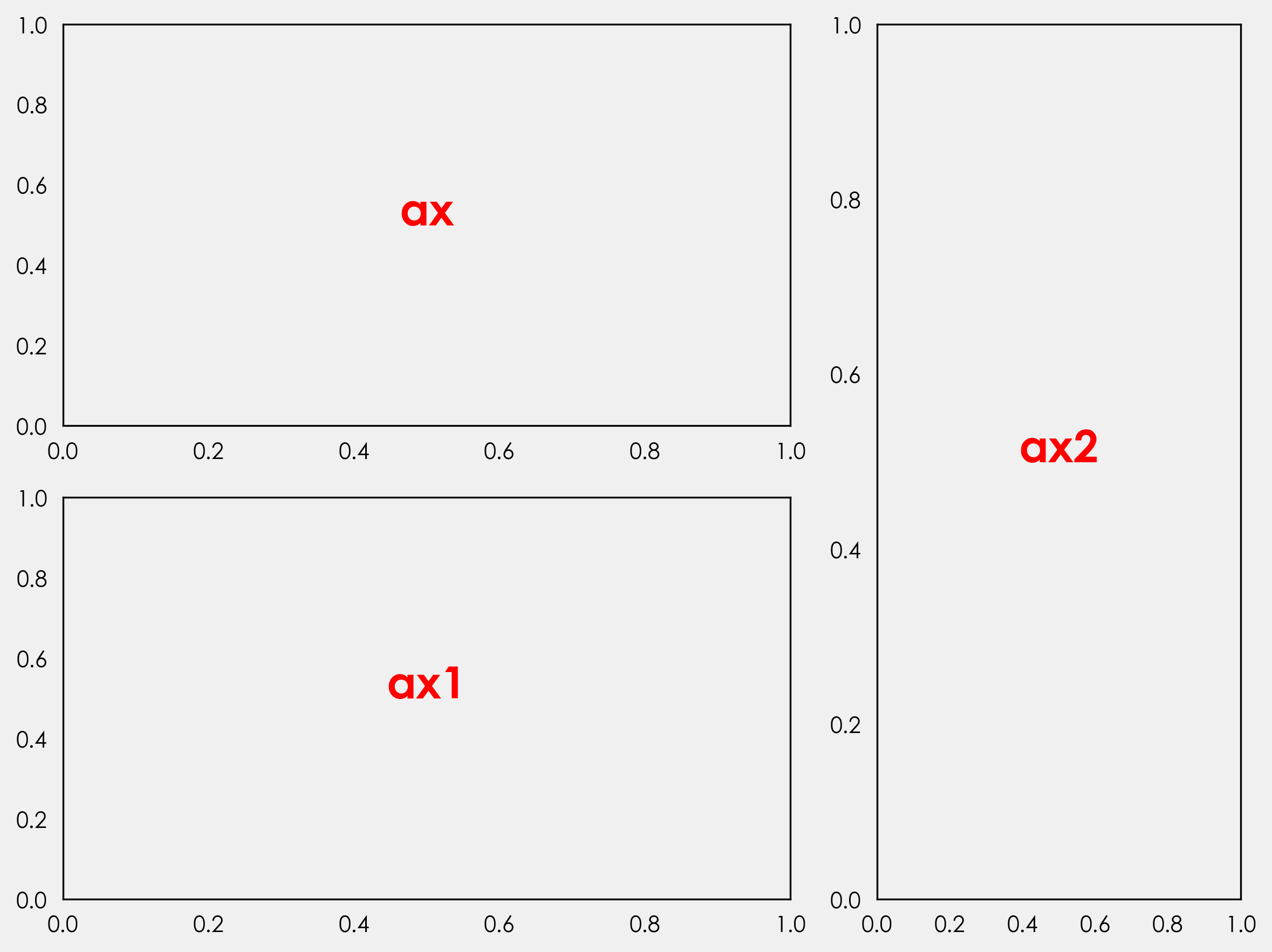
ax1 = plt.Axes(fig=fig, rect=[0.3, 0.3, 0.4, 0.4], facecolor="red")
ax2 = plt.Axes(fig=fig, rect=[0, 0, 1, 1], facecolor="blue")
Now you need to add the Axes to fig. You should stop right here and think about why would there be a need to do this when fig is already a parent of ax1 and ax2? Let’s do this anyway and we’ll go into the details afterwards.
fig.add_axes(ax2)
fig.add_axes(ax1)
<matplotlib.axes._axes.Axes at 0x1211dead0>
# As you can see the Axes are exactly where we specified.
fig
That means you can do this now:
Remark: Notice the ax.reverse() call in the snippet below. If I hadn’t done that, the biggest plot would be placed in the end on top of every other plot and you would just see a single, blank ‘cyan’ colored plot.
fig = plt.figure(figsize=(6, 6))
ax = []
sizes = np.linspace(0.02, 1, 50)
for i in range(50):
color = str(hex(int(sizes[i] * 255)))[2:]
if len(color) == 1:
color = "0" + color
color = "#99" + 2 * color
ax.append(plt.Axes(fig=fig, rect=[0, 0, sizes[i], sizes[i]], facecolor=color))
ax.reverse()
for axes in ax:
fig.add_axes(axes)
plt.show()
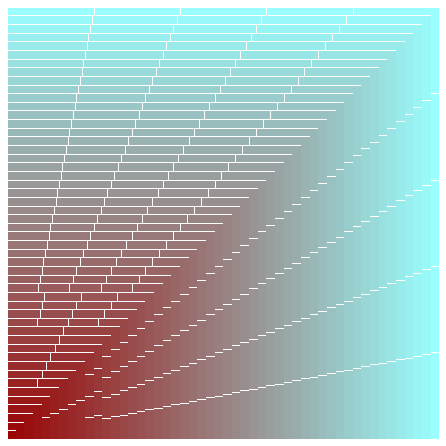
The above example demonstrates why it is important to decouple the process of creation of an Axes and actually putting it onto a Figure.
Also, you can remove an Axes from the canvas area of a Figure like so:
This can be useful when you want to compare the same primary data (GDP) to several secondary data sources (education, spending, etc.) one by one (you’ll need to add and delete each graph from the Figure in succession)
I also encourage you to look into the documentation for Figure and Axes and glance over the several methods available to them. This will help you know what parts of the wheel you do not need to rebuild when you’re working with these objects the next time.
Recreating our subplots literally from scratch
This should now make sense. We can now create our original plt.subplots(2, 2) example using the knowledge we have thus gained so far.
(Although, this is definitely not the most convenient way to do this)
fig = mpl.figure.Figure()
fig
fig.suptitle("Recreating plt.subplots(2, 2)")
ax1 = mpl.axes.Axes(fig=fig, rect=[0, 0, 0.42, 0.42])
ax2 = mpl.axes.Axes(fig=fig, rect=[0, 0.5, 0.42, 0.42])
ax3 = mpl.axes.Axes(fig=fig, rect=[0.5, 0, 0.42, 0.42])
ax4 = mpl.axes.Axes(fig=fig, rect=[0.5, 0.5, 0.42, 0.42])
fig.add_axes(ax1)
fig.add_axes(ax2)
fig.add_axes(ax3)
fig.add_axes(ax4)
fig
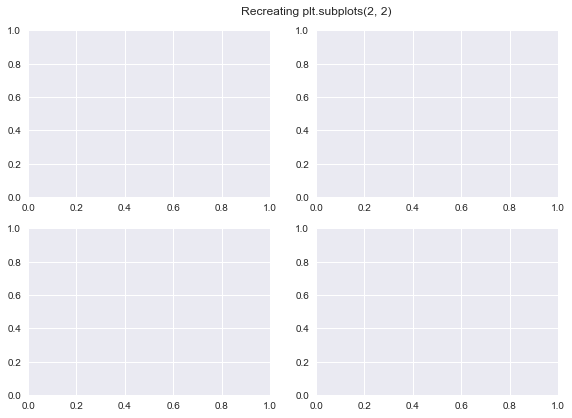
Using gridspec.GridSpec
Docs : https://matplotlib.org/api/_as_gen/matplotlib.gridspec.GridSpec.html#matplotlib.gridspec.GridSpec
GridSpec objects allow us more intuitive control over how our plot is exactly divided into subplots and what the size of each Axes is.
You can essentially decide a Grid which all your Axes will conform to when laying themselves over.
Once you define a grid, or GridSpec so to say, you can use that object to generate new Axes conforming to the grid which you can then add to your Figure
Lets see how all of this works in code:
You can define a GridSpec object like so (both statements are equivalent):
gs = mpl.gridspec.GridSpec(nrows, ncols, width_ratios, height_ratios)
# OR
gs = plt.GridSpec(nrows, ncols, width_ratios, height_ratios)
More specifically:
gs = plt.GridSpec(nrows=3, ncols=3, width_ratios=[1, 2, 3], height_ratios[3, 2, 1])
nrows and ncols are pretty self explanatory. width_ratios determines the relative width of each column. height_ratios follows along the same lines.
The whole grid will always distribute itself using all the space available to it inside of a figure (things change up a bit when you have multiple GridSpec objects for a single figure, but that’s for you to explore!). And inside of a grid, all the Axes will conform to the sizes and ratios defined already
def annotate_axes(fig):
"""Taken from https://matplotlib.org/gallery/userdemo/demo_gridspec03.html#sphx-glr-gallery-userdemo-demo-gridspec03-py
takes a figure and puts an 'axN' label in the center of each Axes
"""
for i, ax in enumerate(fig.axes):
ax.text(0.5, 0.5, "ax%d" % (i + 1), va="center", ha="center")
ax.tick_params(labelbottom=False, labelleft=False)
fig = plt.figure()
# We will try and vary axis sizes here just to see what happens
gs = mpl.gridspec.GridSpec(nrows=2, ncols=2, width_ratios=[1, 2], height_ratios=[4, 1])
<Figure size 576x396 with 0 Axes>
You can pass GridSpec objects to a Figure to create subplots in your desired sizes and proportions like so :
Notice how the sizes of the Axes relates to the ratios we defined when creating the Grid.
fig.clear()
ax1, ax2, ax3, ax4 = [
fig.add_subplot(gs[0]),
fig.add_subplot(gs[1]),
fig.add_subplot(gs[2]),
fig.add_subplot(gs[3]),
]
annotate_axes(fig)
fig

Doing the same thing in a simpler way
def add_gs_to_fig(fig, gs):
"Adds all `SubplotSpec`s in `gs` to `fig`"
for g in gs:
fig.add_subplot(g)
fig.clear()
add_gs_to_fig(fig, gs)
annotate_axes(fig)
fig

That means you can now do this:
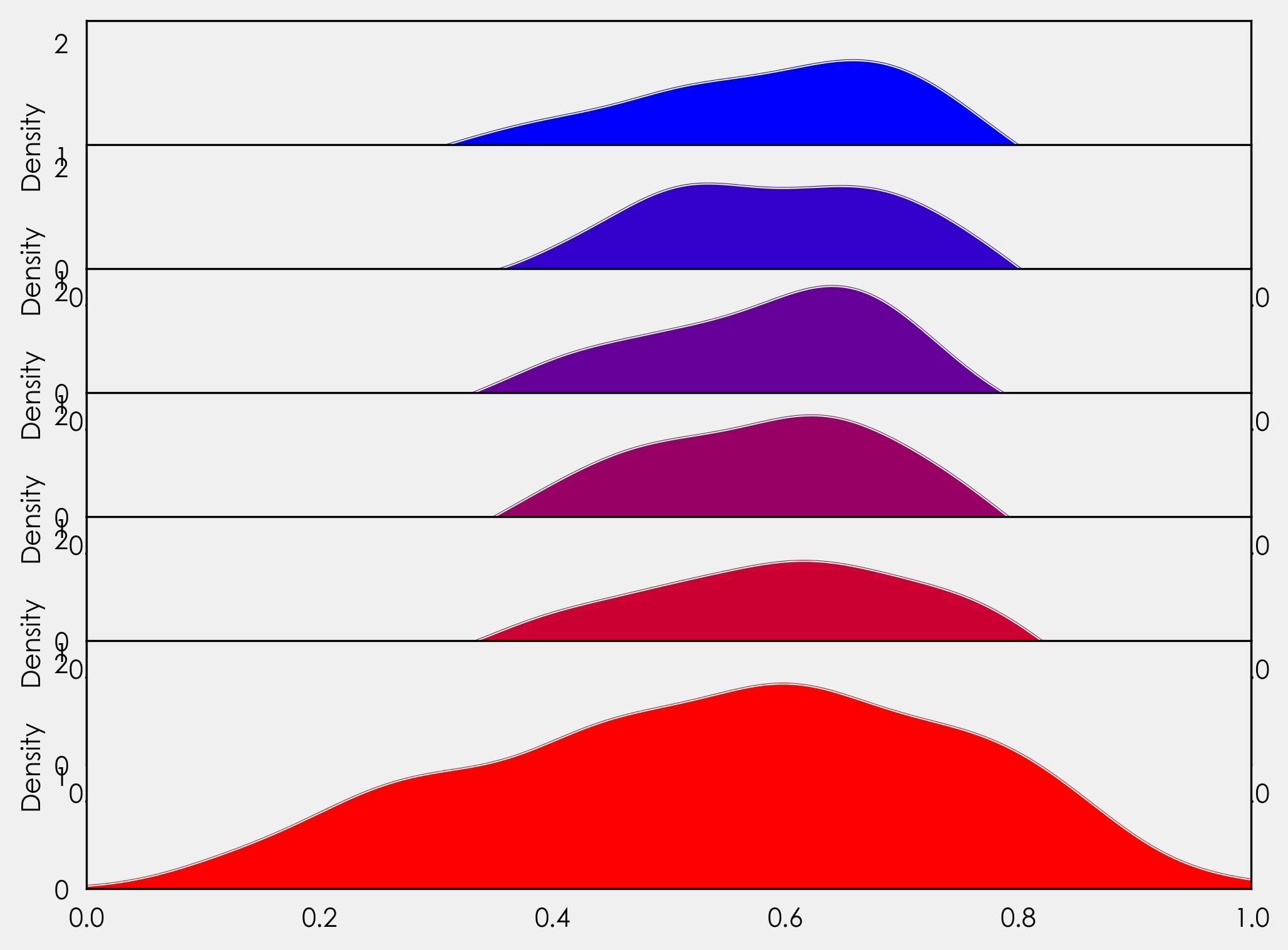
(Notice how the Axes sizes increase from top-left to bottom-right)
fig = plt.figure(figsize=(14, 10))
length = 6
gs = plt.GridSpec(
nrows=length,
ncols=length,
width_ratios=list(range(1, length + 1)),
height_ratios=list(range(1, length + 1)),
)
add_gs_to_fig(fig, gs)
annotate_axes(fig)
for ax in fig.axes:
ax.plot(xs, ys)
plt.show()
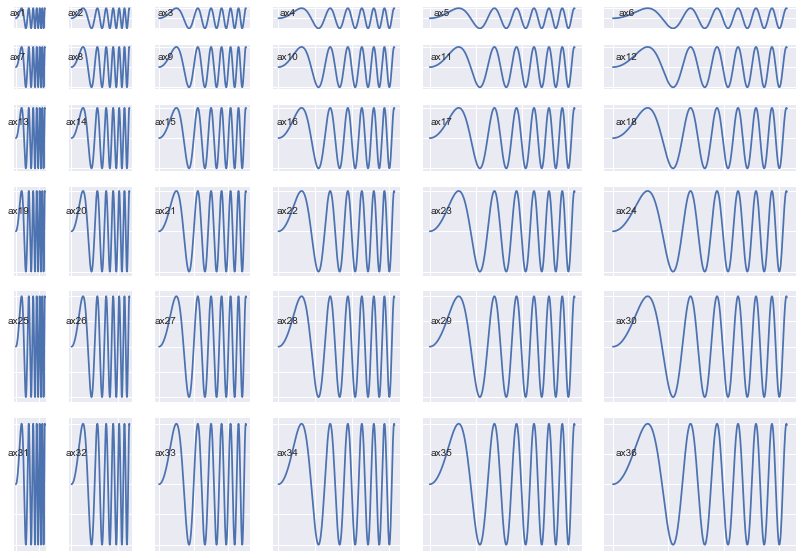
A very unexpected observation: (which gives us yet more clarity, and Power)
Notice how after each print operation, different addresses get printed for each gs object.
gs[0], gs[1], gs[2], gs[3]
(<matplotlib.gridspec.SubplotSpec at 0x1282a9e50>,
<matplotlib.gridspec.SubplotSpec at 0x12942add0>,
<matplotlib.gridspec.SubplotSpec at 0x12942a750>,
<matplotlib.gridspec.SubplotSpec at 0x12a727e10>)
gs[0], gs[1], gs[2], gs[3]
(<matplotlib.gridspec.SubplotSpec at 0x127d5c6d0>,
<matplotlib.gridspec.SubplotSpec at 0x12b6d0b10>,
<matplotlib.gridspec.SubplotSpec at 0x129fc6390>,
<matplotlib.gridspec.SubplotSpec at 0x129fc6a50>)
print(gs[0, 0], gs[0, 1], gs[1, 0], gs[1, 1])
<matplotlib.gridspec.SubplotSpec object at 0x12951a610> <matplotlib.gridspec.SubplotSpec object at 0x12951a890> <matplotlib.gridspec.SubplotSpec object at 0x12951ac10> <matplotlib.gridspec.SubplotSpec object at 0x12951a150>
print(gs[0, 0], gs[0, 1], gs[1, 0], gs[1, 1])
<matplotlib.gridspec.SubplotSpec object at 0x128fad4d0> <matplotlib.gridspec.SubplotSpec object at 0x1291ebbd0> <matplotlib.gridspec.SubplotSpec object at 0x1294f9850> <matplotlib.gridspec.SubplotSpec object at 0x128106250>
Lets understand why this happens:
Notice how a group of gs objects indexed into at the same time also produces just one object instead of multiple objects
gs[:, :], gs[:, 0]
# both output just one object each
(<matplotlib.gridspec.SubplotSpec at 0x128116e50>,
<matplotlib.gridspec.SubplotSpec at 0x128299290>)
# Lets try another `gs` object, this time a little more crowded
# I chose the ratios randomly
gs = mpl.gridspec.GridSpec(
nrows=3, ncols=3, width_ratios=[1, 2, 1], height_ratios=[4, 1, 3]
)
All these operations print just one object. What is going on here?
print(gs[:, 0])
print(gs[1:, :2])
print(gs[:, :])
<matplotlib.gridspec.SubplotSpec object at 0x12a075fd0>
<matplotlib.gridspec.SubplotSpec object at 0x128cf0990>
<matplotlib.gridspec.SubplotSpec object at 0x12a075fd0>
Let’s try and add subplots to our Figure to see what’s going on.
We’ll do a few different permutations to get an exact idea.
fig = plt.figure(figsize=(5, 5))
ax1 = fig.add_subplot(gs[:2, 0])
ax2 = fig.add_subplot(gs[2, 0])
ax3 = fig.add_subplot(gs[:, 1:])
annotate_axes(fig)

fig = plt.figure(figsize=(5, 5))
# ax1 = fig.add_subplot(gs[:2, 0])
ax2 = fig.add_subplot(gs[2, 0])
ax3 = fig.add_subplot(gs[:, 1:])
annotate_axes(fig)
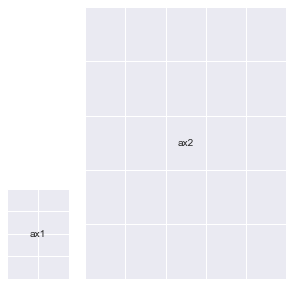
fig = plt.figure(figsize=(5, 5))
# ax1 = fig.add_subplot(gs[:2, 0])
# ax2 = fig.add_subplot(gs[2, 0])
ax3 = fig.add_subplot(gs[:, 1:])
annotate_axes(fig)

fig = plt.figure(figsize=(5, 5))
# ax1 = fig.add_subplot(gs[:2, 0])
# ax2 = fig.add_subplot(gs[2, 0])
ax3 = fig.add_subplot(gs[:, 1:])
# Notice the line below : You can overlay Axes using `GridSpec` too
ax4 = fig.add_subplot(gs[2:, 1:])
ax4.set_facecolor("orange")
annotate_axes(fig)

fig.clear()
add_gs_to_fig(fig, gs)
annotate_axes(fig)
fig

Here’s a bullet point summary of what this means:
gs can be used as a sort of a factory for different kinds of Axes.- You give this
factory an order by indexing into particular areas of the Grid. It gives back a single SubplotSpec (check type(gs[0]) object that helps you create an Axes which has all of the area you indexed into combined into one unit.
- Your
height and width ratios for the indexed portion will determine the size of the Axes that gets generated.
Axes will maintain relative proportions according to your height and width ratios always.- For all these reasons, I like
GridSpec!
This ability to create different grid variations that GridSpec provides is probably the reason for that anomaly we saw a while ago (printing different Addresses).
It creates new objects every time you index into it because it will be very troublesome to store all permutations of SubplotSpec objects into one group in memory (try and count permutations for a GridSpec of 10x10 and you’ll know why)
Now let’s finally create plt.subplots(2,2) once again using GridSpec
fig = plt.figure()
gs = mpl.gridspec.GridSpec(nrows=2, ncols=2)
add_gs_to_fig(fig, gs)
annotate_axes(fig)
fig.suptitle("We're done!")
print("yayy")
yayy

What you should try:
Here’s a few things I think you should go ahead and explore:
- Multiple
GridSpec objects for the Same Figure.
- Deleting and adding
Axes effectively and meaningfully.
- All the methods available for
mpl.figure.Figure and mpl.axes.Axes allowing us to manipulate their properties.
- Kaggle Learn’s Data visualization course is a great place to learn effective plotting using Python
- Armed with knowledge, you will be able to use other plotting libraries such as
seaborn, plotly, pandas and altair with much more flexibility (you can pass an Axes object to all their plotting functions). I encourage you to explore these libraries too.
This is the first time I’ve written any technical guide for the internet, it may not be as clean as tutorials generally are. But, I’m open to all the constructive criticism that you may have for me (drop me an email on akashpalrecha@gmail.com)
]]>








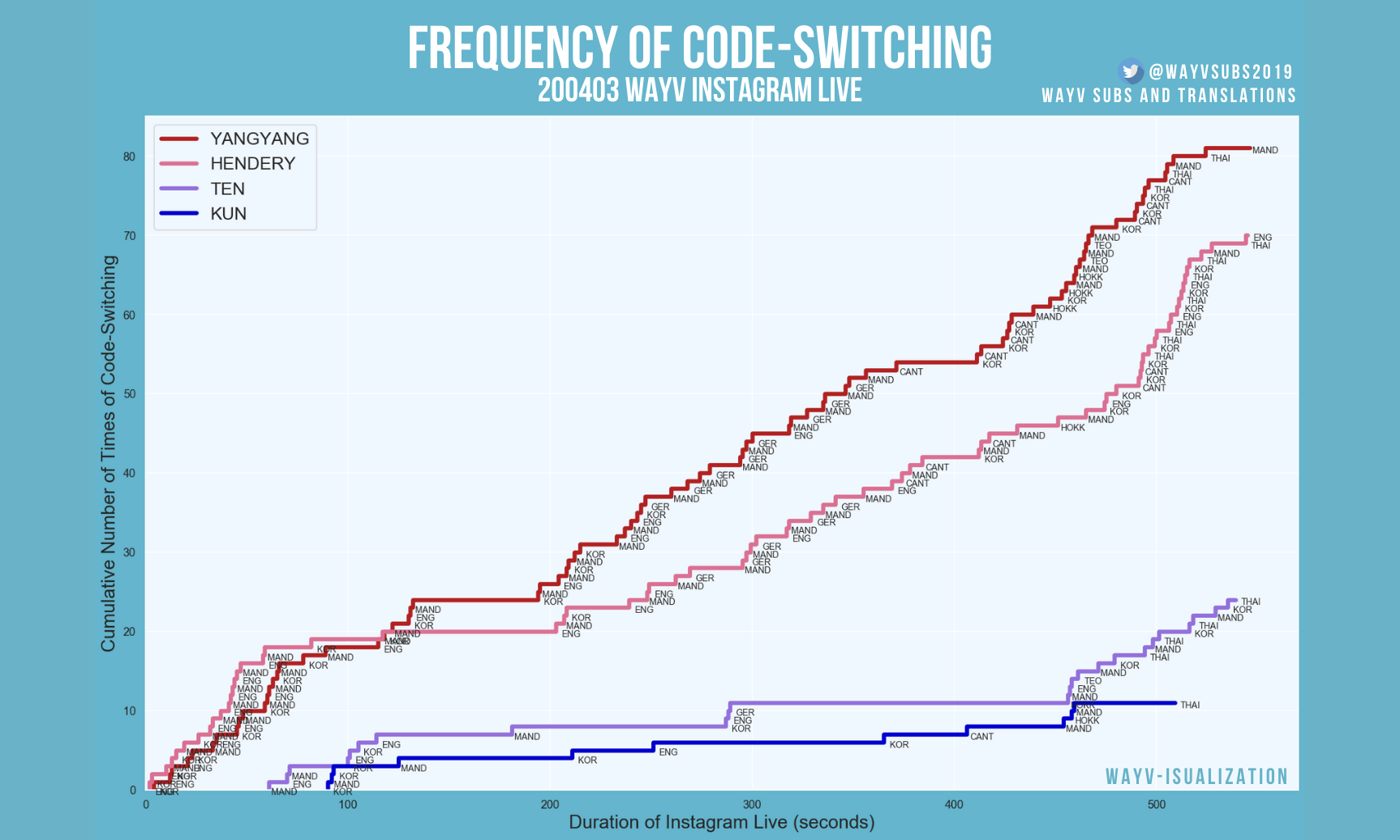
![An all-white graph with the x and y axis defined on the range [0, 1].](/matplotlib/codeswitching-visualization/fig1.png)